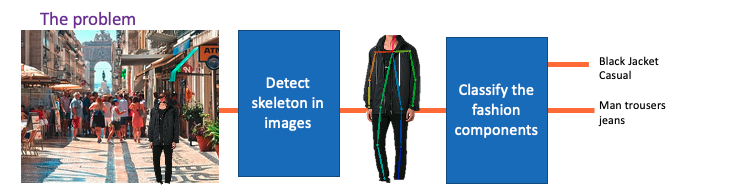
A fashion classifier that anyone can build and run
If you did not read about the gRPC Maestro orchestrator first refer to the platform page
A multilabel CNN-based classifier for fashion attributes
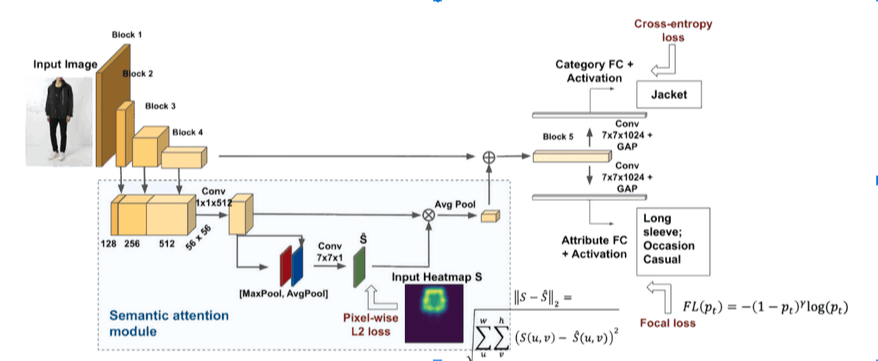
The Tag My Outfit service predicts the category and the attributes of a clothing item present in a given image. The prediction model called Visual Semantic Attention Model (VSAM) pubished in [Ferreira et al 19] was presented at the Computer Vision for Fashion Workshop@ICCV2019.
VSAM is a compact framework with guided attention for multi-label classification in the fashion domain. This model is supervised by automatic pose extraction creating a discriminative feature space.

Skeleton-driven attention

VSAM uses extra information from a pose detection system to learn the relevant image regions, focusing its discriminative power on distinctive areas. This attention mechanism helps VSAM avoid background artifacts, contours or other salient regions unrelated to the outfit.
Network architecture
VSAM regularizes the VGG-16 backbone network with ground-truth heatmaps with relevant joints.
The regularization is performed on the feature combination from the VGG-16 convolutional blocks 2, 3 and 4, applying a 1×1 convolution for feature selection and re-weighting.
Finally, a spatial attention block highlights informative regions. The model is trained end-to-end by minimizing the cross-entropy loss, weighted by class frequency, for the category level, and the focal loss for the attributes level.
To this loss function, we add the regularization term with the L2-norm pixel-wise difference between the estimated heatmap at layer S and the ground truth heatmap S
The processing workflow
Tag-my-outfit is one example of how non-AI-skilled professionals can use these assets with a minimum effort and fast.

Instructions and code in the GitHub repository.
A previous version of this module is available in AI4EU platform. This asset was developed by Duarte Alves and Beatriz Ferreira. Contacts and history see the old Physical AI webpage.